
La Divisione Marketing della Deutsche Bank, sempre alla ricerca di soluzioni innovative, utilizza SUADES per identificare il gradimento dei prodotti da parte dei clienti.
Tramite la matrice generata da SUADES “cliente/prodotto/rate” individua tutti i clienti ai quali uno specifico prodotto “piace” di più oppure quali sono i prodotti più “graditi” da uno specifico cliente.
Le informazioni sono utilizzate:
- per effettuare campagne di marketing mirate
- dai gestori dei clienti tramite CRM per proporre nuovi prodotti o fornire informazioni mirate al momento giusto
- su home banking
- per inviare SMS o mail personalizzate
- su mobile tramite app geo localizzate
- per analisi statistiche
- per prevedere il gradimento di nuovi prodotti
- per attuare azioni di survey su Clienti a rischio di abbandono
- per fidelizzare i Clienti
Per raggiungere le migliori performance SUADES analizza diversi dati di ogni cliente:
- i prodotti già posseduti
- il ciclo di vita
- lo status economico
- lo stile di relazione fra cliente e banca
- i cambiamenti intervenuti recentemente nella situazione finanziaria del cliente
In Figura 1 è riportata una schermata di SUADES con i feedback utilizzati.
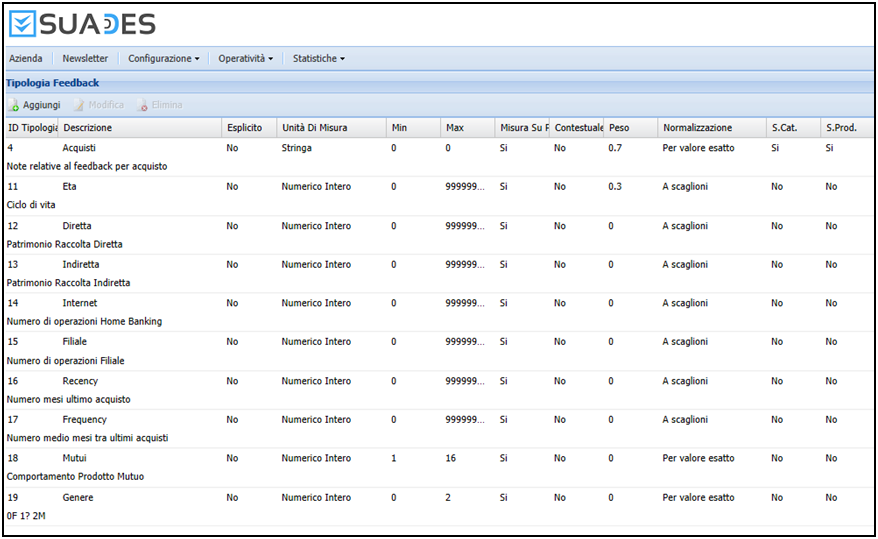
Figura 1. Feedback utilizzati dal sistema SUADES
Il servizio viene erogato in modalità non invasiva: periodicamente vengono inviati i dati dei clienti a CONQUIST che provvede ad elaborarli tramite SUADES ed a restituire alla banca la matrice “cliente/prodotto/rate”.
La banca può accedere da remoto al sistema, per effettuare in maniera autonoma qualsiasi tipo di analisi, tarando a proprio piacimento i vari parametri di SUADES.
Algoritmi
Sono considerati due tipi di algoritmi, entrambi del tipo “collaborative filtering”, cioè basati sull’approccio collaborativo.
Questi algoritmi appartengono a due famiglie:
- Collaborative user-based
- Collaborative item-based
Gli algoritmi del tipo collaborativo “user-based” effettuano il confronto fra ogni coppia di righe della matrice dei dati di partenza (cioè i clienti) calcolando una misura quantitativa di similarità.
In questo modo identificano gruppi di clienti simili, ovverosia clienti con preferenze simili (che tendono ad acquistare gli stessi prodotti finanziari).
Per stimare la probabilità di acquisto di ogni prodotto da parte di ogni cliente utilizzano i dati disponibili relativi al gruppo di clienti simili.
Gli algoritmi del tipo collaborativo “item-based” effettuano il confronto fra ogni coppia di colonne della matrice dei dati di partenza (cioè i prodotti) anche in questo caso attraverso una metrica di similarità.
L’algoritmo identifica gruppi di prodotti simili, ovverosia prodotti che tendono ad essere acquistati dagli stessi clienti. Anche in questo caso la stima della probabilità di acquisto viene effettuata utilizzando l’insieme dei dati identificato grazie alla similarità.
Misure di similarità
Sono state implementate nel Sistema di Raccomandazione quattro diverse misure di similarità:
- Pearson Correlation
- Euclidean Distance
- Spearman Correlation
- Log Likelihood
Il coefficiente di correlazione di Pearson si ottiene dividendo la covarianza (la covarianza è una misura di dipendenza) fra due serie di dati per il prodotto delle deviazioni standard di ogni serie (la deviazione standard è una misura di dispersione).
Ad esempio, se si considera un algoritmo di tipo user-based, ogni serie di dati descrive le informazioni relative ad un cliente.
La similarità fra due clienti è ottenuta dunque dividendo la covarianza fra i due clienti per il prodotto delle deviazioni standard di ogni cliente.
La distanza euclidea è ottenuta considerando due serie di dati (ad esempio due clienti), calcolando le differenze fra componenti analoghe (ad esempio la differenza fra le età dei clienti), sommando i quadrati delle differenze e calcolando la radice quadrata.
Il coefficiente di correlazione di Spearman può essere considerato una variante del coefficiente di Pearson adatto a variabili di tipo ordinale. Questo tipo di metrica può essere particolarmente utile nel caso dei Sistemi di Raccomandazione quando le preferenze dei clienti sono espresse attraverso “rating” espressi in una scala a valori interi (ad esempio, una scala a cinque valori come accade in molti siti Web).
Il test Log-Likelihood è una statistica che, in generale, un test statistico che consente di affermare con una certa probabilità che due modelli sono identici. Il test fornisce, dunque, anche una metrica per calcolare la similarità fra due modelli, o due serie di dati.
Ampiezza del vicinato
Poiché gli algoritmi utilizzati sfruttano la similarità fra clienti o la similarità fra prodotti, è importante identificare il numero di oggetti (clienti o prodotti) simili da considerare per effettuare la stima della probabilità di acquisto.
Suades è utilizzato facendo variare il numero di oggetti simili considerati, ovverosia la “ampiezza del vicinato” (neighborhood nella terminologia tecnica).
Sono considerati due criteri:
- Nearest N User
- Threshold User
Il primo criterio, Nearest N User, consiste nel fissare esplicitamente il numero di oggetti simili da considerare.
Il secondo criterio, Threshold User, prevede invece che sia fissata una soglia di similarità: l’algoritmo considera solo i clienti (o i prodotti) che presentano un valore di similarità inferiore alla soglia (il numero di clienti è dunque variabile e non predeterminabile).
In Figura 2 è riportato uno schema delle attività effettuate attraverso i primi tre parametri.
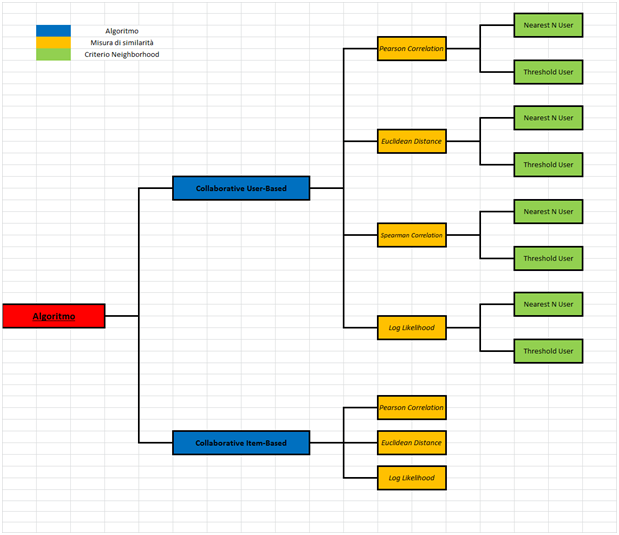
Figura 2. Schema degli algoritmi, metriche di similarità, criteri di ampiezza del vicinato considerati.
Indicatori di performance
Sono considerati tre indicatori di performance:
- Precision
- Recall
- F-Measure
La Precision è il rapporto tra il numero di raccomandazioni previste correttamente (i prodotti con probabilità di acquisto elevata che sono state effettivamente acquistati dai clienti) e il numero di raccomandazioni totali (tutti i prodotti con probabilità di acquisto elevata).
La Recall è il rapporto tra il numero di raccomandazioni previste correttamente (lo stesso numeratore della Precision) e il numero di acquisti totale (tutti i prodotti acquistati dal cliente).
La F-measure (F) è una combinazione delle altre due calcolata come il doppio del rapporto fra il prodotto di Precision e Recall diviso per la somma di Precision e Recall.
Figura 3 riporta uno schema di calcolo di Precision e Recall.
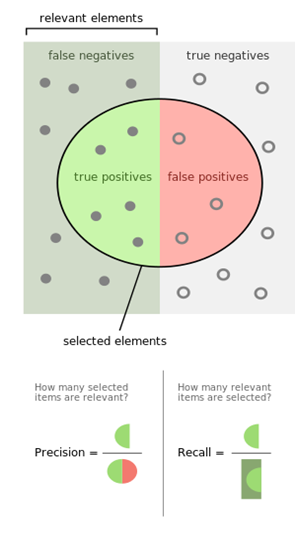
Figura 3. Schema di calcolo di Precision e Recall.
Per informazioni: info@conquist.it